
如何通过快捷键快速提升日常办公效率
在信息爆炸的时代,职场人平均每天要切换应用窗口400余次,处理邮件30封以上,重复执行复制粘贴操作近200次。这些看似零散的操作,若用传统鼠标点击完成,累计耗时可达工作总时长的30%。当...

如何辨别主板上的显卡插槽类型
随着计算机硬件技术的飞速发展,显卡作为图形处理的核心部件,其性能与主板插槽的匹配度直接影响整机表现。显卡插槽的接口类型历经多次迭代,从早期的ISA、AGP到主流的PCI-E,不同接口在传...
如何在揭阳住房公积金管理中心现场激活账户
住房公积金账户的激活是职工享受公积金服务的前提,也是保障个人住房权益的重要步骤。在揭阳市,住房公积金管理中心为市民提供了便捷的线下激活服务,但许多人对具体流程、材料准备及注...

lunago如何处理邮箱被举报的情况
lunago处理邮箱被举报的情况时,应首先保持冷静,并根据实际情况采取一系列应对措施。以下是一些具体的建议: 1. 明确举报内容及其性质: 仔细分析举报信的内容,了解被举报的具体事项。 判...

如何礼貌询问邻居调低音乐音量
夏日的夜晚,楼道里忽然传来节奏强烈的电子音乐,穿透墙壁的声波在客厅里形成共振。这种场景在城市公寓中并不鲜见,英国《噪音控制期刊》2021年的研究显示,全球高层住宅区中,63%的住户曾...

如何判断膝关节是否需要手术
判断膝关节是否需要手术,通常需要综合考虑多个因素,包括但不限于患者的症状、关节功能、影像学检查结果以及患者的整体健康状况。以下是一些关键点: 1. 症状的严重性: 日常活动受限:...
咪咕盒子初次使用如何完成网络连接设置
随着智能家居设备的普及,家庭影音娱乐系统逐渐从传统有线电视转向互联网电视盒子。作为中国移动推出的智能终端产品,咪咕盒子凭借海量影视资源和操作便捷性受到用户青睐。首次使用该设...
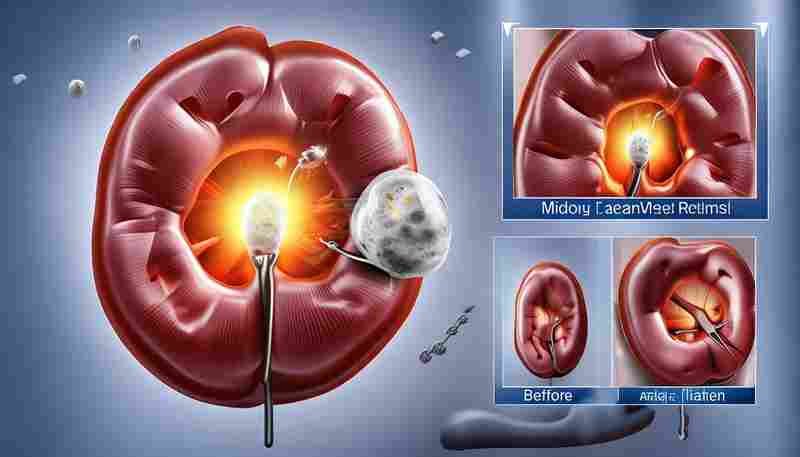
肾结石体积与位置如何影响治疗方案的选择
肾结石作为泌尿系统的高发疾病,其治疗方案的制定并非“一刀切”,而是基于结石体积、位置、成分及患者个体特征的精密权衡。现代医学通过影像技术精准评估结石参数,结合微创技术发展,...
猎人如何分离信标怪避免BOSS回血
在《魔兽世界》奥杜尔副本的零灯尤格萨隆战斗中,第三阶段的信标怪机制堪称团队存亡的关键。信标怪一旦处理不当,不仅会导致BOSS持续回血,还可能因治疗压力剧增引发团灭。猎人作为远程职...

如何使用手机应用修改QQ密码
1. 打开QQ应用 :在您的手机上找到并打开QQ应用。确保您已经安装了最新版本的QQ应用。 2. 登录账户 :输入您的QQ号码和当前密码,完成登录过程。 3. 进入设置 :登录成功后,点击右下角的“我”...

转账限额超出如何解决
遇到转账限额超出的问题,可以通过以下几种方法解决: 1. 线上自助解除: 如果已开通手机银行,可以登录手机银行APP,在“银行卡管理”或“账户管理”中找到“限额设置”,然后调整转账限...

使用辅助圆球截图时如何添加注释
使用辅助圆球(如iOS设备上的小白点或类似功能)截图时,若想在截图上添加注释,可以按照以下步骤进行(以iOS设备为例): 1. 完成截图: 使用辅助圆球或其他截图方式完成截图操作。在iOS设...

如何更新万能遥控器的数据库
更新万能遥控器的数据库通常涉及几个通用步骤,虽然具体操作可能因品牌和型号而异。以下是一个概括性的指南,结合了不同设备和数据库更新的一般流程: 1. 连接互联网:确保你的遥控器或其...
如何调整微信附近的人的搜索距离范围
在移动社交时代,微信“附近的人”功能为用户提供了拓展本地社交圈的可能性。不少用户发现,默认的搜索范围可能无法满足特定需求——有人希望扩大距离以接触更多人群,也有人倾向于缩小...

如何优化人物相册的照片尺寸以适应不同平台
1. 了解各平台的尺寸要求 :需要熟悉每个社交媒体平台对照片尺寸的具体要求。例如,Facebook推荐的图片尺寸为1080×1350像素,而Instagram则推荐1080×1080像素。了解这些要求有助于确保照片在各个平...
微信支付解绑后如何彻底清除交易记录
在数字支付渗透日常生活的今天,个人金融数据的管理成为公众关注焦点。微信支付作为国内使用率最高的移动支付工具之一,其交易记录不仅包含消费金额、时间等基础信息,更可能关联着用户...
如何从启动U盘安装Windows系统
1. 准备工作 : 准备一个容量至少为8GB的U盘,并确保其中没有重要数据,因为制作启动U盘会格式化U盘。 下载Windows操作系统的ISO镜像文件,可以从微软官方网站或其他合法渠道获取。 2. 制作启动...

孩子情绪失控时如何用轻声耳语安抚
当孩子因情绪失控而哭闹时,许多父母的第一反应是试图用音量压制孩子的情绪,但心理学研究表明,过高的声调反而会加剧孩子的紧张感。若父母能俯下身、放低音量,用轻柔的语调与孩子对话...

如何修改小米手机来电显示的时间格式
修改小米手机来电显示的时间格式通常涉及调整系统的时间设置。根据提供的参考内容,虽然没有直接提及来电显示时间格式的设置方法,但可以推测,因为来电显示的时间格式一般跟随系统设置...

如何在锁屏界面显示音乐控制选项
要在锁屏界面显示音乐控制选项,可以根据不同的手机品牌和系统进行设置。以下是一些常见手机品牌的具体设置方法: OPPO手机: 1. 进入手机的“设置”页,找到并点击“便捷辅助”选项。 2....